Overcoming Memory Limitations in Generative AI: Managing Context Windows Effectively

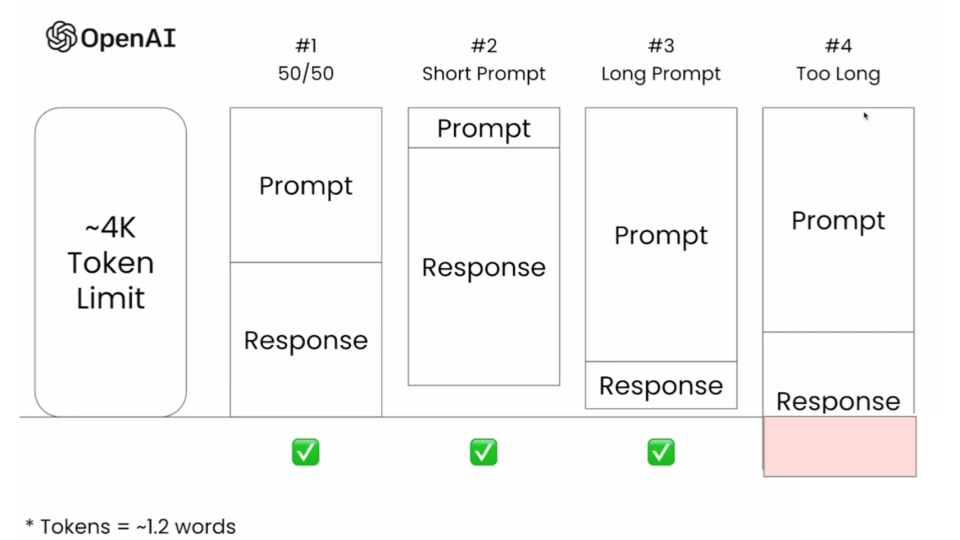
Large language models (LLMs) like GPT-4 and Claude excel at generating human-like text, but they face a critical limitation: no inherent memory. Every interaction requires developers to supply relevant context within a fixed token capacity called a context window. While these windows have grown from 1K to over 1M tokens, managing them remains a challenge—especially for long conversations or complex tasks. This blog explores practical strategies to overcome these limitations and optimize LLM performance.

Understanding the Challenge
LLMs rely entirely on the context provided in each prompt to generate responses. Key issues include:
- Token Limits: Context windows cap the combined size of input (prompt) and output (response). Exceeding this limit degrades response quality.
- Context Truncation: Long conversations force developers to omit older context, leading to incoherent or irrelevant outputs.
- Cost and Latency: Larger context windows increase computational costs and slow response times.
For example, a 4K token window forces tough trade-offs: include more history for coherence or prioritize recent input for relevance.
Methods to Manage Context Windows
1. Extended Context Models
What: Use models with larger native context windows (e.g., Gemini’s 1M tokens, Claude 3’s 200K).
Pros: Simplest solution; minimal engineering effort.
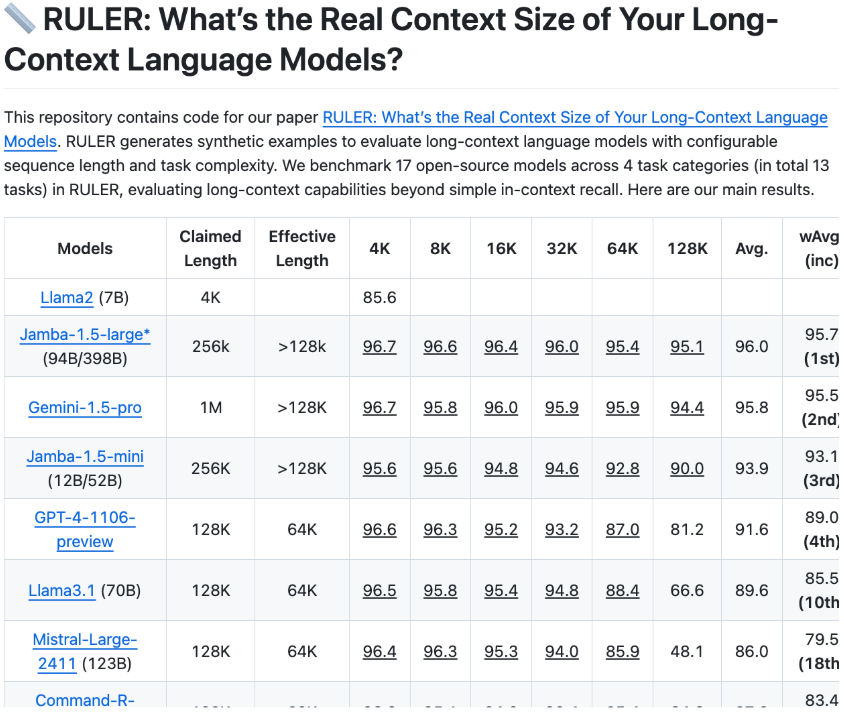
Cons: Costly for frequent interactions; not all models deliver on claimed capacities (verify via benchmarks like NVIDIA’s Context Window Ruler).
2. Chunking & Sliding Windows
What: Split long inputs into smaller segments. Use sliding windows with overlapping tokens to preserve continuity.
Example: A 10K-token document split into four 3K chunks with 500-token overlaps.
Pros: Maintains sequential coherence; scalable.
Cons: Requires multiple API calls; risks losing global context.
3. Summarization
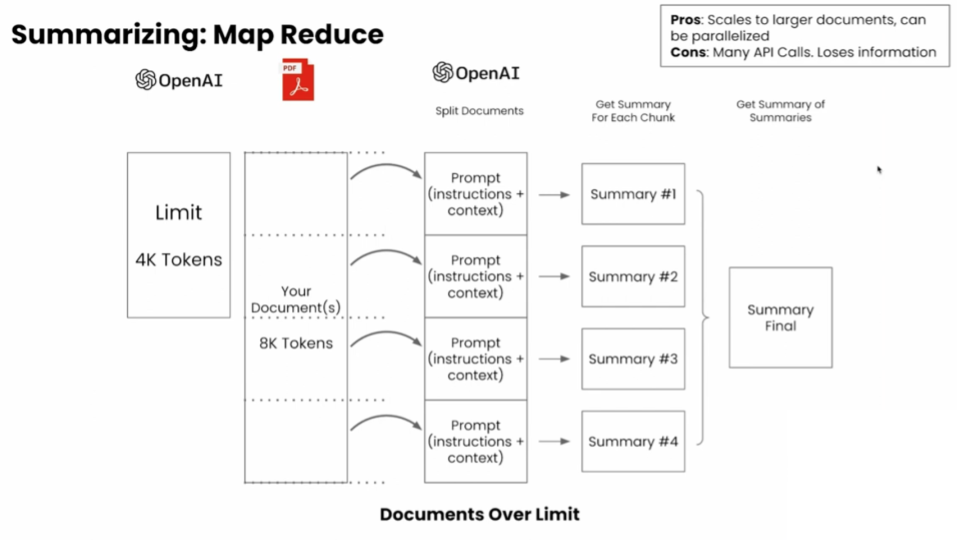
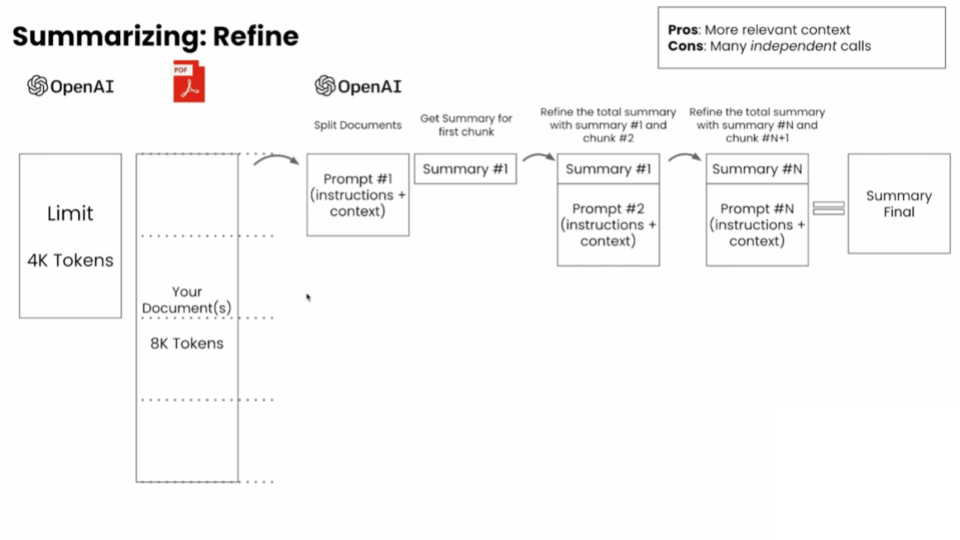
What: Compress chunks into summaries using techniques like map-reduce (parallel summarization) or refine (sequential summarization).
Use Case: Summarizing chat history to retain key points without full context.
Pros: Reduces token usage; maintains thematic relevance.
Cons: Risk of information loss; adds latency.
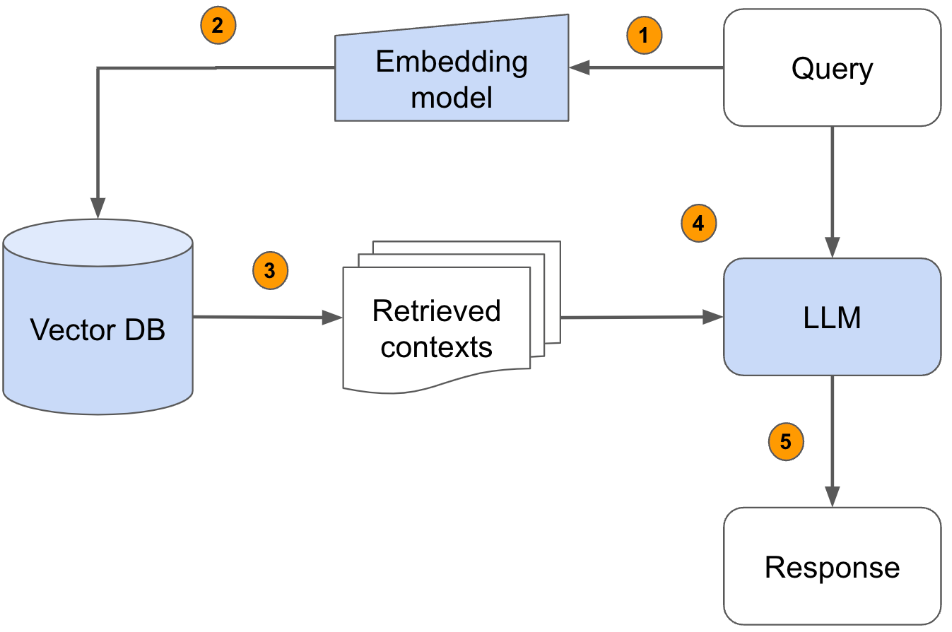
4. Retrieval-Augmented Generation (RAG)
What: Use a vector database to store embeddings of context chunks. Retrieve only semantically relevant sections for each query.
Tools: LangChain, LlamaIndex, PG Vector.
Pros: Dynamic context selection; scalable for large datasets.
Cons: Requires embedding models and vector DB infrastructure.
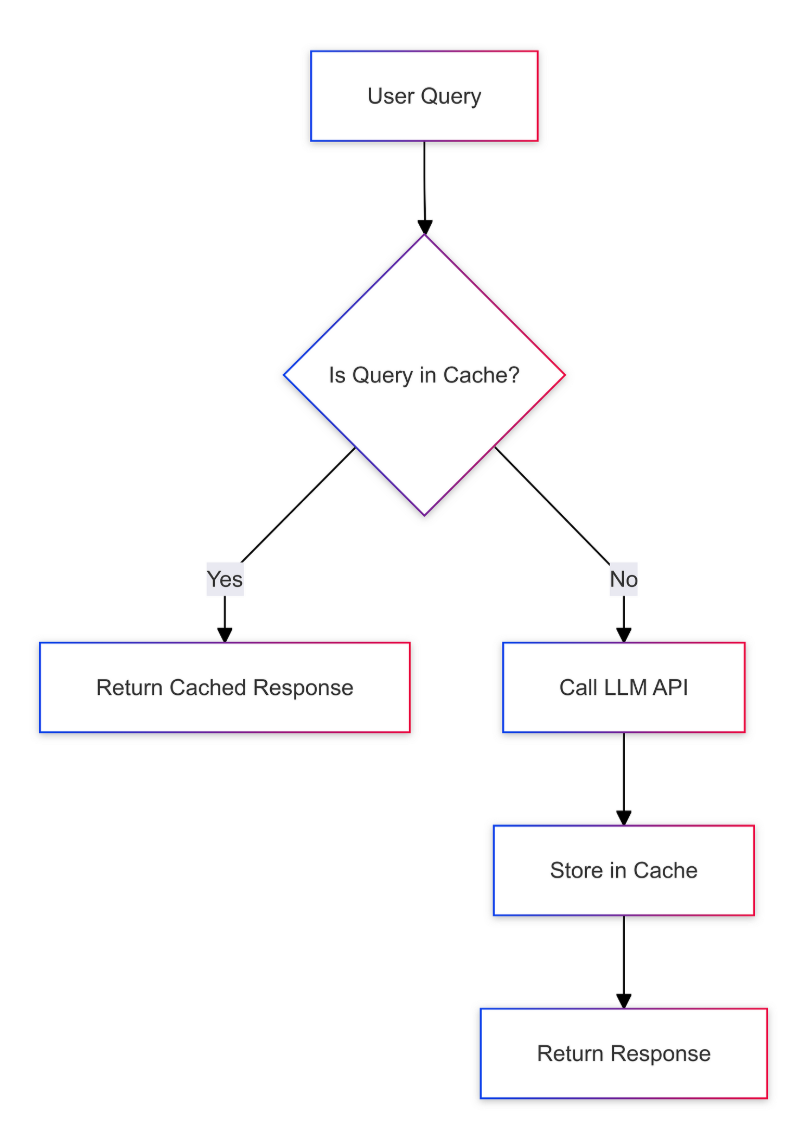
5. Memory Buffers & Caching
What: Store critical entities or preferences in a key-value cache (e.g., user preferences in ChatGPT).
Use Case: Chatbots recalling user-specific details (e.g., "My dog is named Fabio").
Pros: Lightweight; customizable.
Cons: Limited to predefined entities; manual updates.
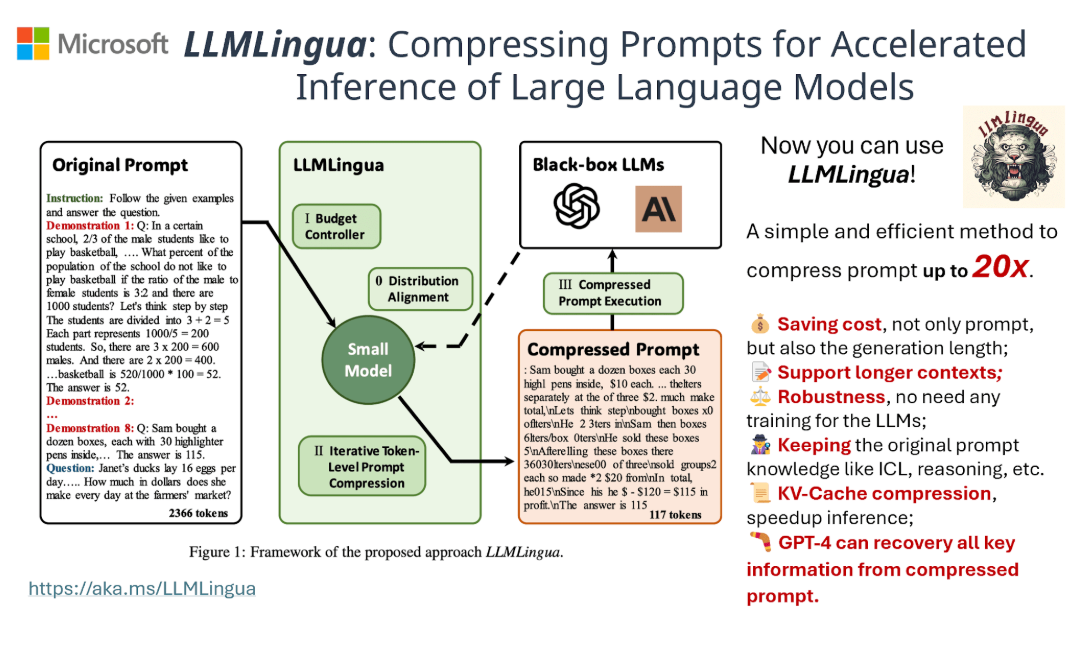
6. Prompt Compression
What: Remove filler words, whitespace, and redundant phrases without losing meaning. Tools like LLM Lingua (Microsoft Research) automate this.
Example: Compressing "Please summarize the following document..." to "Summarize doc: [text]."
Pros: No architectural changes; significant token savings.
Cons: Requires testing to avoid over-compression.
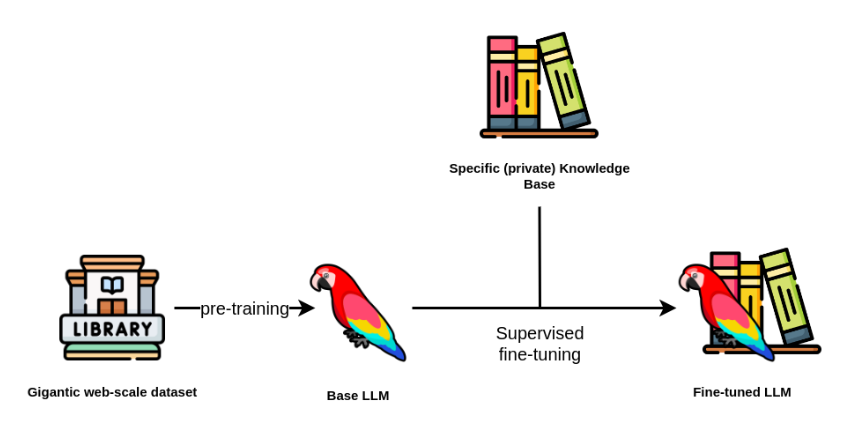
7. Fine-Tuning
What: Train a base model on domain-specific data to reduce reliance on prompt context.
Use Case: Healthcare or legal LLMs with specialized knowledge.
Pros: Long-term memory for niche domains.
Cons: Expensive; requires labeled data and ML expertise.
Comparison of Methods
| Method | Complexity | Cost | Context Retention | Best For |
|---|---|---|---|---|
| Extended Context Models | Low | High | High | Simple, short-term tasks |
| Chunking | Moderate | Medium | Moderate | Sequential data (e.g., logs) |
| RAG | High | Medium | High | Scalable QA systems |
| Prompt Compression | Low | Low | High | Cost-sensitive applications |
Best Practices
- Combine Methods: Use RAG with summarization or caching for optimal efficiency.
- Monitor Trade-offs: Balance cost, latency, and accuracy (e.g., cheaper models for summarization, GPT-4 for final outputs).
- Benchmark Performance: Test different approaches with domain-specific queries.
Emerging Trends
- Infinite Context Research: Techniques like "rolling attention" (distributed processing) aim to eliminate token limits.
- Specialized LLMs: Models pre-trained for verticals (e.g., finance, coding) reduce reliance on context windows.
Conclusion
While no single solution eliminates context window challenges, strategic combinations of chunking, RAG, and compression can mitigate limitations. As models evolve, expect innovations like infinite context and better fine-tuning tools to push LLMs closer to "true memory." For now, prioritize experimentation and stay updated on tools like LLM Lingua and vector databases.