Getting to 99.999% Accuracy: Options for Narrow-Use LLM Tools

At DEFCON on August 11, Chief Digital and AI Officer for DoD Dr. Craig Martell spoke about large language models (LLMs) and their future use at the Department of Defense (DoD). In that talk he said the following about the need for accuracy: “I need five nines [99.999% accuracy] of correctness…I cannot have a hallucination that says: ‘Oh yeah, put widget A connected to widget B’ — and it blows up.”
Achieving this level of accuracy is likely not feasible currently, although it depends on the narrowness of your goal and what your data looks like. But advancements in base models might make it possible in the future.
And you can certainly start thinking about approaches to development and assessment. You can build the necessary test and evaluation infrastructure, and you can get used to solving these problems in lower-stakes contexts so that if it does become possible, you’ll be ready to go.
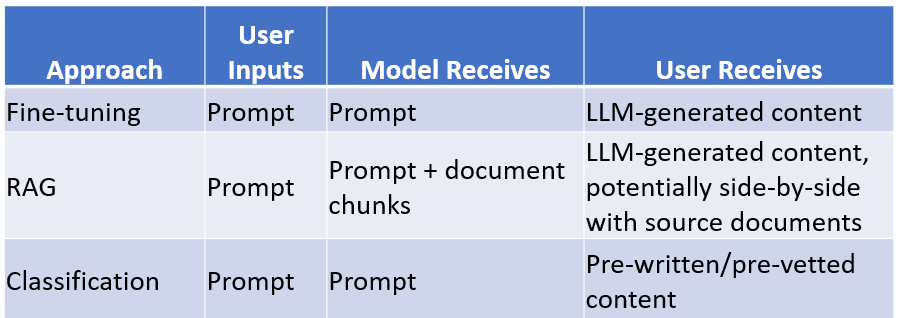
In this post, I discuss three different approaches to this problem and what developers would need from DoD to build and assess each approach. In all of these approaches, the end result is a tool where a soldier can ask a question and immediately get back a text response.
For example, it could be an IT tool guiding soldiers on computer troubleshooting or, aligning better with Dr. Martell’s use case, a tool instructing users on bomb defusal. Each of these approaches provides performance assessment data for the tool. However, there are significant differences among these approaches in functionality, complexity, and the client's data and labor requirements.
These three approaches, from greatest to least technical sophistication, are the following.
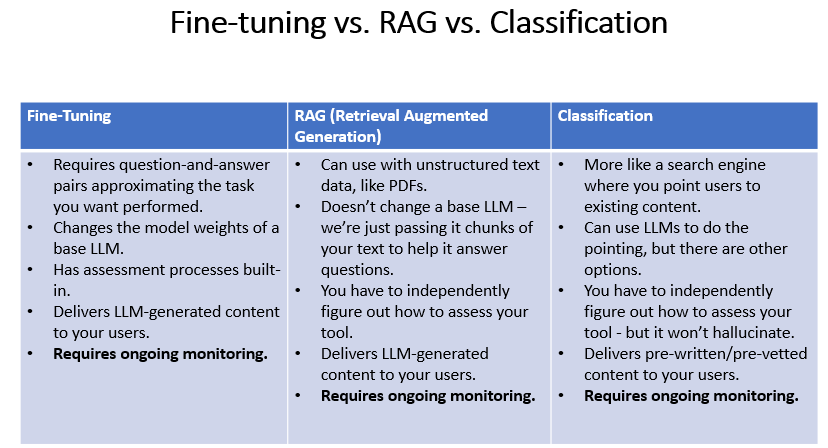
- Fine-tuning a base model, where you take labeled data approximating the kinds of questions you want the tool to be able to answer, and the answers you want it to give, and you train an existing model with this data.
- Retrieval Augmented Generation, or using a chatbot with unstructured data. Chunks of unstructured data are used as context, which are then passed to the model to help it answer the question, but the model itself is not modified.
- A classification model combined with pre-generated text, where the text itself has been written (potentially by an LLM) and vetted ahead of time, and the model is just determining which set of text is appropriate to the question. There are multiple ways to construct this, which might involve training an LLM, constructing a prompt to use with an LLM, or using a non-LLM option like comparing the similarity of a user prompt to a pre-existing list of possible prompts.
Each of these methods can also be paired with a first-step classification model using an LLM to determine whether the question is within the scope of what the tool can answer. That is, before you even use this tool, you screen each user prompt. If the prompt isn’t the type of question that your model can answer, it tells the user this and returns no other output. Only if the prompt passes does the main tool see it and output a response.
All of these should also be paired with ongoing monitoring and assessment to make sure that users are interacting with the tool as expected, and that it's continuing to perform as it did in initial testing.
It may also be the case that there are no existing models which can currently provide this degree of accuracy for the kind of use case Dr. Martell is envisioning. For instance, for the bomb-defusing example, maybe an LLM can’t currently provide the level of guidance necessary to be useful, either because of current limits to base model performance or because the DoD doesn’t have the necessary data to train it or desire to create training data and perform assessment.
Regardless, it’s still possible to gather or generate the kind of data and build the necessary training and assessment infrastructure now such that, if better models become available, you’ll be ready to utilize them.
Fine-Tuning a Base Model
Fine-tuning involves adapting a base model, such as Llama-2 or GPT-3.5, by training it on new labeled data for a designated task. In this case, the labeled data would need to consist of question-answer pairs – the type of questions you want the tool to be able to answer, and corresponding correct answers. Some of the labeled data you use to train the model, and some of it you hold back in order to assess its performance after training.
The end result of this process is a model that’s a slightly-tweaked version of the base model - that is, it has different model weights – as well as performance metrics showing how well it does. The performance metrics use specific tools for comparing the actual output that the tool gives to the correct, or desired, outputs. (These can also be combined with human judgment.)
Fine-tuning is both the most technically-sophisticated option and the one where you can most quickly assess tool performance. This is because you initially split your data into training data and assessment data, so after you train your model, you can identify how well it performs on the questions that you left out of the training process. The end result is a model trained for a specific task, and where the user experience is also the most seamless – the same experience as interacting with a base LLM.
However, this approach requires a specific type of data that likely doesn’t exist for most use cases: extensive data mimicking what kinds of questions a user will ask, and the responses the tool should give them.
The question for DoD is: do you have existing data that approximates the types of interactions you want users to be having with this tool?
In some cases, you might. For instance, if you’re trying to replace (or partially replace) an existing customer service process with an LLM, or if you have existing training processes which have, as artifacts, pairs of data corresponding to questions that a soldier might ask paired with good answers, then this might be for you.
Alternatively, if this kind of data doesn’t exist already, you could create it. You could have experts create question-answer pairs. You could have practitioners or trainees generate questions they would like to ask, and then have experts write just the answers. You will probably wind up supplementing this by hiring contractors just to label data for you.
And if you think the base LLM already can perform the tasks without any additional training, you can skip the fine-tuning and go straight to assessment. In this case, your labeled data serves solely as a kind of benchmark – a test to see what a model can do, not data you’re using to actually modify it.
But also, you’re probably going to need a lot of high-quality data to be confident that you’re hitting five nines of accuracy. How much data depends on how you interpret that 99.999% figure.
Does it mean that the tool can correctly answer 99.999% of all valid English questions? That’s not possible at this point, given current LLM capabilities. If it were, you could potentially rely on broad, existing benchmarks for LLMs.
Does it mean 99.999% of the set of questions that an average soldier might ask this tool? In that case, you need high-quality data about the kinds of questions that a soldier might use it for, and what the correct answer is. For instance, what if the vast majority of user prompts can be answered by a small number of response types? Let’s say you’re trying to approximate an IT tool that always either tells you to either call into the help desk or restart your computer.
In that case, you might not actually need tons of labeled data for assessment – but on the other hand, if that were your problem, you probably wouldn’t need an LLM. In a more realistic scenario, you’re going to need a lot of data just for the assessment piece, in addition to the training piece.
Retrieval Augmented Generation (RAG)
What if you don’t have labeled data and don’t want to create it – but you do have a lot of unstructured text data, like textbooks and manuals, and you want your soldiers to be able to ask it questions? If that’s your use case, you might want to create a retrieval-augmented generation (RAG) tool. This doesn’t train or modify an existing LLM, but gives it additional information to answer your users’ questions in the form of excerpts from your unstructured text data, which are then passed to the LLM, along with their question.
This is an explanation of when you might use RAG and how it works:
We want to create a chatbot which lets users ask questions just about a specific corpus of information, like the documentation for a software package or a set of regulations or all of the documents living on their organization’s intranet.
Maybe these are private or recent documents that aren’t in the training corpus of any LLMs; maybe they are, but because the LLM knows so many other things as well, when we ask questions specifically about these documents, it gets mixed up and gives us answers about other documents as well.
We don’t want to go through the trouble of fine-tuning a model, or actually modifying the LLM itself – maybe for lack of expertise or compute resource, maybe because our data is not in a format that would let us do this
Instead, we segment our unstructured data and design a tool to identify the most relevant text chunks related to our query, which is then sent to the LLM along with the question. The LLM now has our question and, hopefully, the text it needs to answer that question.
Retrieval-augmented generation is a much more flexible tool than fine-tuning a model, in the sense that you can throw your data at it without parsing it into question-and-answer pairs. It’s also not especially computationally-intensive - that is, it doesn’t take much memory, since you’re not actually changing the underlying model, you’re just processing your data and then feeding chunks of it to the model. However, this simplicity comes with a set of problems, particularly when you want to talk about assessment. Unlike with fine-tuning, you can’t hold back labeled data for assessment because you don’t have labeled data.
So how do you assess your tool? You have a couple of options:
- Generate some labeled data – not to fine-tune, but enough to assess. But, like with the fine-tuning problem, that’s likely going to involve generating a lot of high-quality data.
- Go straight to user testing as a way of generating labeled data. That is, have users try out your tool, potentially in a training context (so that nothing actually explodes if the tool is wrong), and have experts rate the answers.
With RAG, you also have the option of using the fact that the answers are coming from known text chunks as part of your user interface. That is, you can present the LLM-generated text side-by-side with the sources – the sections from your original unstructured text data – and give both to the user.
You can then treat the outcome not as what the LLM says to do but what the user actually does. That is, you could score a result as a pass if the LLM told the user to do something wrong, but the user saw the actual source documents and realized the result was incorrect.
I don’t like this. I think that results like this might not generalize out to actual use. That is, if the user knows that the tool isn’t reliable, or feels like their performance is being assessed as much as the tool’s is, they might pay attention to the source documents in a way that they might not in an actual scenario. However, there could be contexts where this is appropriate.
Pre-Generated Text Paired with a Classification Model
This is the least-ambitious approach. You can think of this more like using a search engine than an LLM, in that you’re pointing users to existing, pre-vetted data rather than presenting them with newly-generated data.
It’s also the approach where you can most easily get to 99.999% – or even 100% – although the way to get there arguably relies on quite a bit of cheating – that is, by counting it as a success if your tool outputs coherent, vetted content, even if that coherent, vetted content isn’t actually relevant to your question.
Let’s go back to the very simple earlier hypothetical example of an IT language tool where the answer is always either “restart your computer” or “call the helpline.”
If those are the only two possible answers, you don’t actually need to give your users text that an LLM has generated specifically for them. Instead, you’re just trying to route them to a correct answer. This is called a classification model: you’re classifying the text a user gives us and putting it in a particular bucket, either “restart” or “helpline”.
This is what that tool creation process could look like.
First, you write some text that you will give to users explaining either that they should restart their computers or call the helpline. Maybe you use an LLM to help you generate that text.
When a user interacts with the tool, you route them to the correct piece of text. There are various ways you could accomplish that.
- You could have a prompt that you feed to a base LLM describing under what circumstances the answer should be “restart” and under what it should be “helpline”. Depending on that result, you determine which full text response to send to the user.
- You fine-tune a classification model. For this, you need labeled data – but the labeled data isn’t the full response, it’s just “restart” or “helpline”, and then you output the corresponding full text. This is basically using topic modeling or glorified keyword searches to classify the user prompts.
- You use text similarity metrics rather than an LLM. You have a list of chunks of text describing different scenarios and what the corresponding correct resolution is. For each user input, you find the most similar scenario and output the correct corresponding piece of text.
- You use keyword searches to look for specific words in the text, and route it accordingly.
But regardless of your classification method, the actual output is pre-vetted: that is, it’s a piece of text that’s already been determined to not be a hallucination. It’s a correct answer 100% of the time–but it might not be the correct answer to the question you asked.
A classification model can have more than two possible categories. The situations where it has many are those where the LLM’s ability to generate text is the most useful, even though that text will still have to be assessed by a person.
Your broader assessment options - that is, for determining whether the tool has actually given the user the correct text for that output – look a lot like for RAG: you can either create labeled data for assessment, or you can go straight to user testing and generate your labeled data via that process.
Supplementing With A First-Stage Classification Model
For each scenario, no single model can provide accurate answers to all possible questions. That is, if you ask it something totally outside of the scope of the tool, you wouldn’t expect it to give good answers.
Because of this, you should add a step where you first assess whether the question can even be answered by your tool – and you pair this with any of the three approaches.
You can do this by compiling a data set of in-scope and out-of-scope prompts – basically, a list of the kind of questions you want your tool to be able to answer, vs. those you don’t. You can then take a base LLM and fine-tune it on your data, the same way as I described in the first approach.
Your labeled data in this case is a set of prompts that are in-scope, and the classification result or answer “in-scope”, and then examples of prompts you wouldn’t want your tool to try to answer, and then answer “not in scope”. For out-of-scope prompts, you would give users a prewritten piece of text, like in the final approach, warning them that their prompt was not something the tool could answer. For in-scope prompts, you would then send the prompt to the tool and output the answer for the user.
This is the approach that deepset, an AI startup, explains in this blog post: it’s for detecting prompt injection attempts, or attempts to trick or derail a tool, but the general premise holds for detecting unintentionally out-of-scope prompts as well.
If you need to get to 99.999% with current LLM capabilities, you need to define that 99.999% as being 99.999% of in-scope queries, not queries overall – and you need a narrow sense of what’s in-scope and what’s not. Because the easiest way to get your accuracy numbers up is to reduce the set of questions your tool will attempt to answer.
But if you’re anticipating that there may be a next generation of more capable LLMs, you can also automatically tie this step in with your training and assessment step if you’re using the fine-tuning approach: that is, if the base LLM gets better such that the base LLM + fine-tuning can handle a wider array of use cases, then you can connect that to your first step and automatically loosen your classification criteria such that you allow your tool to handle a wider set of prompts as it improves.
Getting Contractors Cleared for Data Labeling
I’ve talked a lot about data labeling here — whether you have labeled data and how you might generate it if you don’t. To some extent, you might generate that data via your own existing workforce, either by having them explicitly label data or via interacting with tools and providing feedback.
But labeling data is time-intensive, and so if you want tools with high accuracy — or even just tools you can assess precisely — you’re going to wind up outsourcing much of that work to contractors. And the OpenAI outsourcing solution is not an option because of rules around government contracting in general, and also because of many of those contractors will need clearances. There aren’t currently a lot of companies in that space. As you think about the supply chain necessary to develop these narrow-use LLM tools, this is one piece to think about.
Conclusion
Getting to 99.999% accuracy in your narrow-use LLM tool - for the DoD, or anyone else - requires a combination of a lot of labeled data, a precise sense of what you want your tool to do, and manpower for testing and evaluation. And it might still not be possible yet for this type of task – but the easiest way to get closer is to limit the scope of what the tool will answer, like via a first step which classifies prompts as in-scope or out-of-scope and refuses to answer the out-of-scope questions.
There are more questions I’d want to ask about what it means to deploy a narrow-use tool in a set of circumstances where, if the answer is wrong, something blows up. For instance, what is this tool replacing, and what’s its accuracy level? What problem are you trying to solve?
But this is a beginning: a few possible approaches, and what you and your developers would need to work on together to get there.