Govpinions: Exploring Public Comments on Federal Regulations
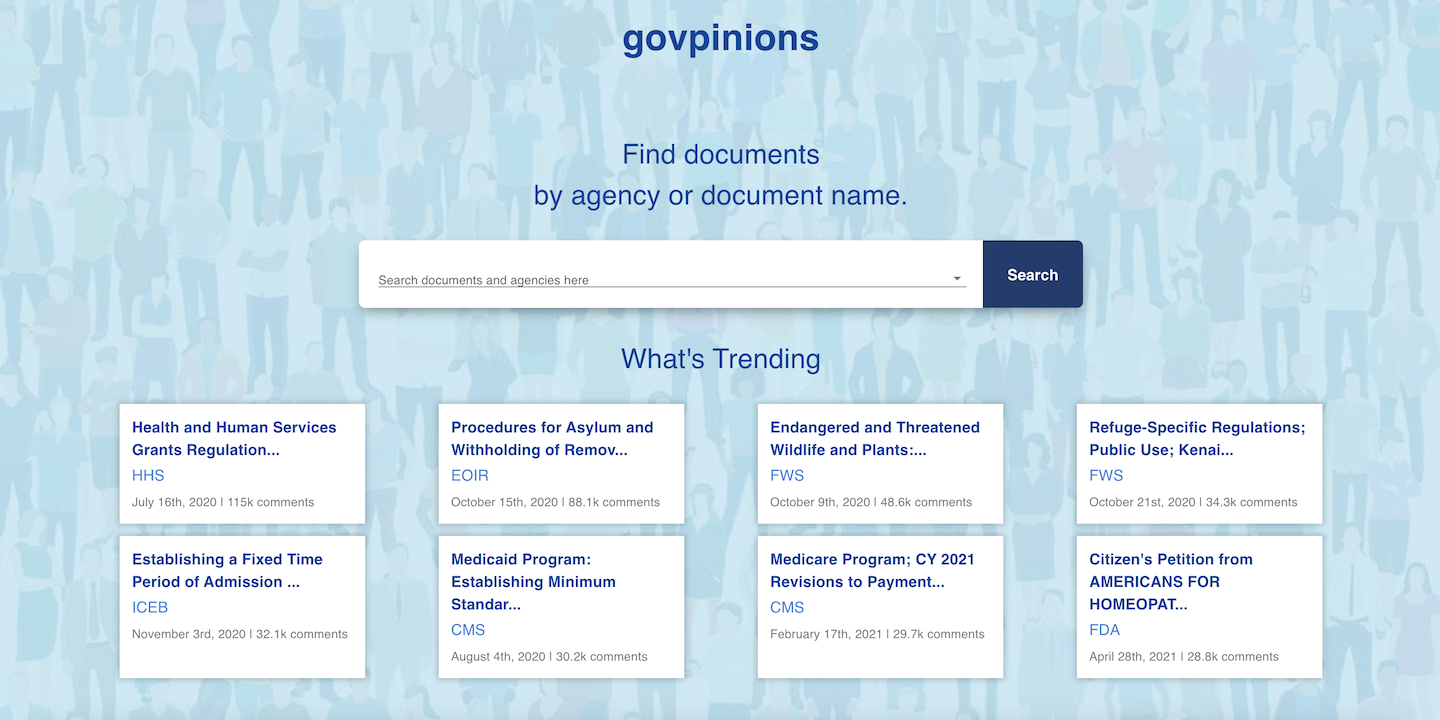
Over eight short weeks, four of our talented interns—Aiden Nguyen, Hadas Hirt, Adam Janicki and Estee Brooks—developed a beta version of Govpinions to easily visualize and analyze patterns in public comments on government regulations.
Understanding the Problem
We'll start with a quick refresher on the U.S. government. The legislative branch, i.e. Congress, sets the policy direction of the country by making laws. Once that vision is established, it's the responsibility of the executive branch to execute it. To do so, it has several departments, which contain a variety of agencies, and numerous ever-more-specific subdivisions.
In many cases, before any of these units implement new regulations, members of the public are given the chance to weigh in. Government officials take into account the feedback they receive before making final rules on topics ranging from water cleanliness standards to drug policy to Internet traffic standards.
Historically, it has been hard to analyze these public comments. For one thing, there can simply be a large number of comments to wade through, especially for more contentious topics. It can also be hard to find comments about a given topic, though regulations.gov has helped with that.
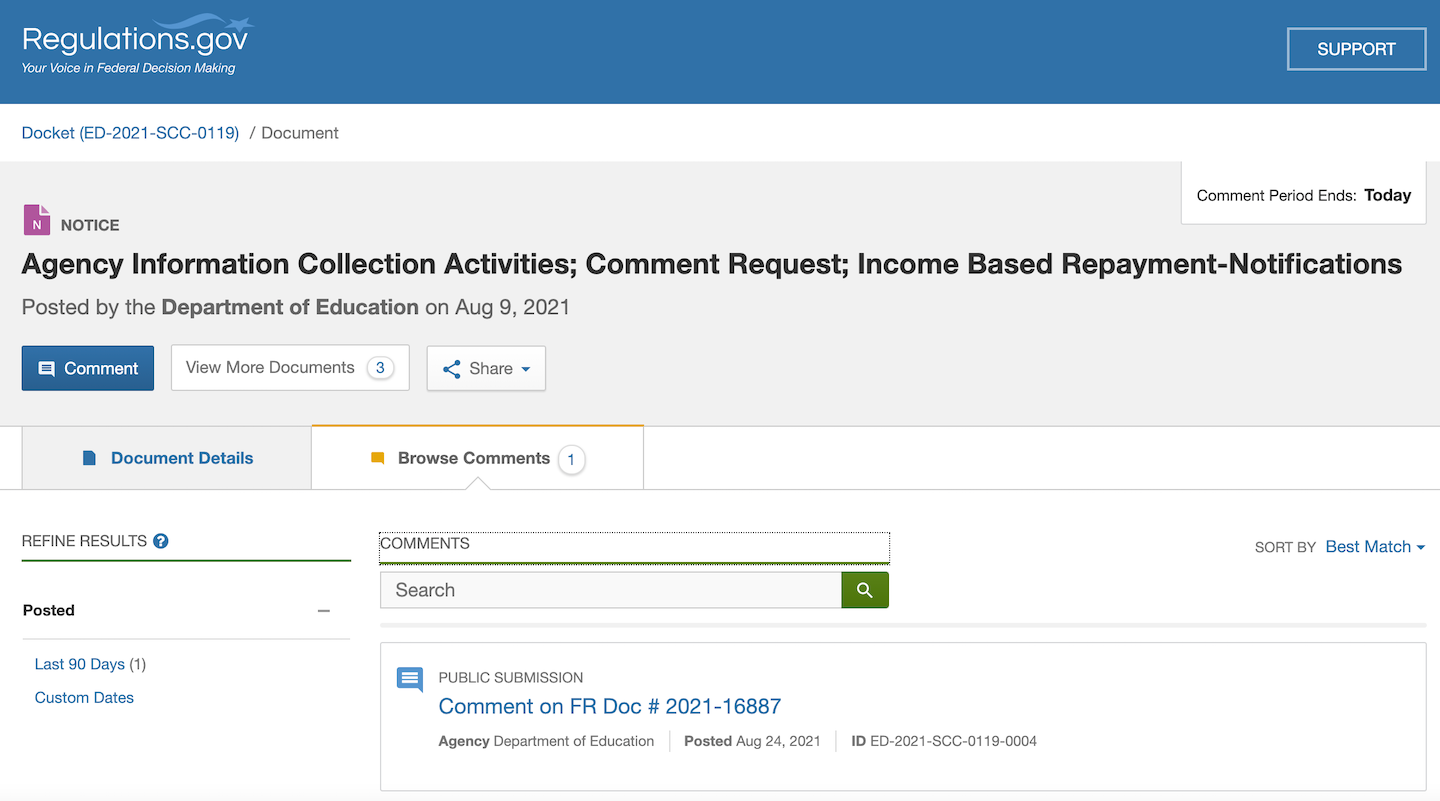
More recently, modern communication technologies have made it easier than ever for Americans to submit comments. Gone are the days of hand-writing one's opinions about proposed rules, looking up obscure government addresses and licking stamps. The low friction and wide availability of the Internet has led some people, often with the best of intentions, to create pre-filled forms that people can sign and submit with one click.
However, this causes problems for federal employees and policymakers. Should they give more weight to a comment written longhand, containing personalized contents, and received in a physical envelope, or an e-mail containing text they've seen hundreds of times before, which the sender might not have even read? Most people agree that copy-pasted messages should be considered less valuable.
This year, our interns worked on making those public comments more useful and easy to understand.
Technical Approach
As with any data project, the interns' first step was to gather the actual data. In this case, they did so by retrieving a year's worth of public comments using the API at regulations.gov.

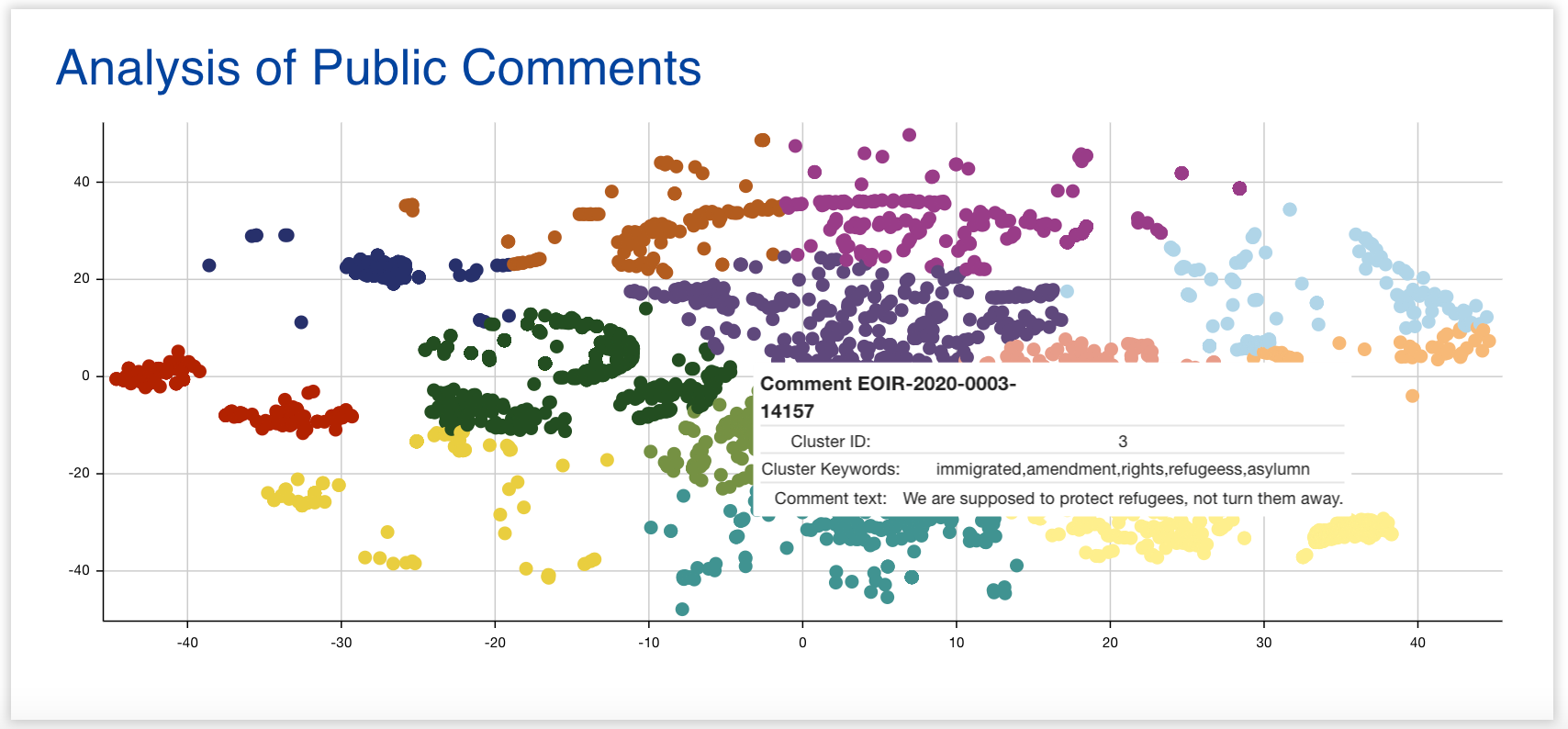
Before processing the data, the interns needed to first format the comments in a way that machine learning (ML) algorithms could use for natural language processing (NLP), and save them in a database. To achieve this, they cleaned the comments and stripped them of stopwords (words with little information content like "the" or "an"), and stemmed them down to their “roots” to reduce noise. Then, the interns used the Universal Sentence Encoder to encode the comments numerically based on their semantic meaning. Next, they applied dimensionality reduction algorithms (PCA and then t-SNE) to reduce the encodings from 512 dimensions down to two. The interns ran the cleaned, encoded and reduced data through K-means Clustering, an ML algorithm which clusters data based on similar semantic meaning. Finally, keyBert was used to extract representative words from each cluster as a whole.
Once the data were processed, and the testing cycle of ML was mostly in place, the interns made their results available on the Internet for the public to use. Their next challenge was to create a website for data visualizations using TypeScript, React, Next.js, D3Plus and other modern web technologies in order to best represent their findings in a sleek, user-friendly and intuitive way.
Why this Work Matters
One of the benefits of Govpinions is its visual presentation of what we call rings. Remember those pre-filled forms from earlier? It would be easy for a computer to check whether two comments were exact duplicates, but not helpful, because the signatures are different in many form letters. Some more motivated template users may also add a few extra comments or change some details they don't fully agree with. These comments are all still more closely related to each other than to comments written from scratch by completely unrelated people. We termed these groups of similar comments "rings", and our machine learning algorithm detects them. On the website, one can hover over a unique point on the graph to see whether or not it’s classified as part of a ring. Often, ring clusters take unusually circular form - and differ from the more organic shape of a typical cluster. This can help federal employees quickly scan a graph, and identify the most critical areas of recurring public feedback.
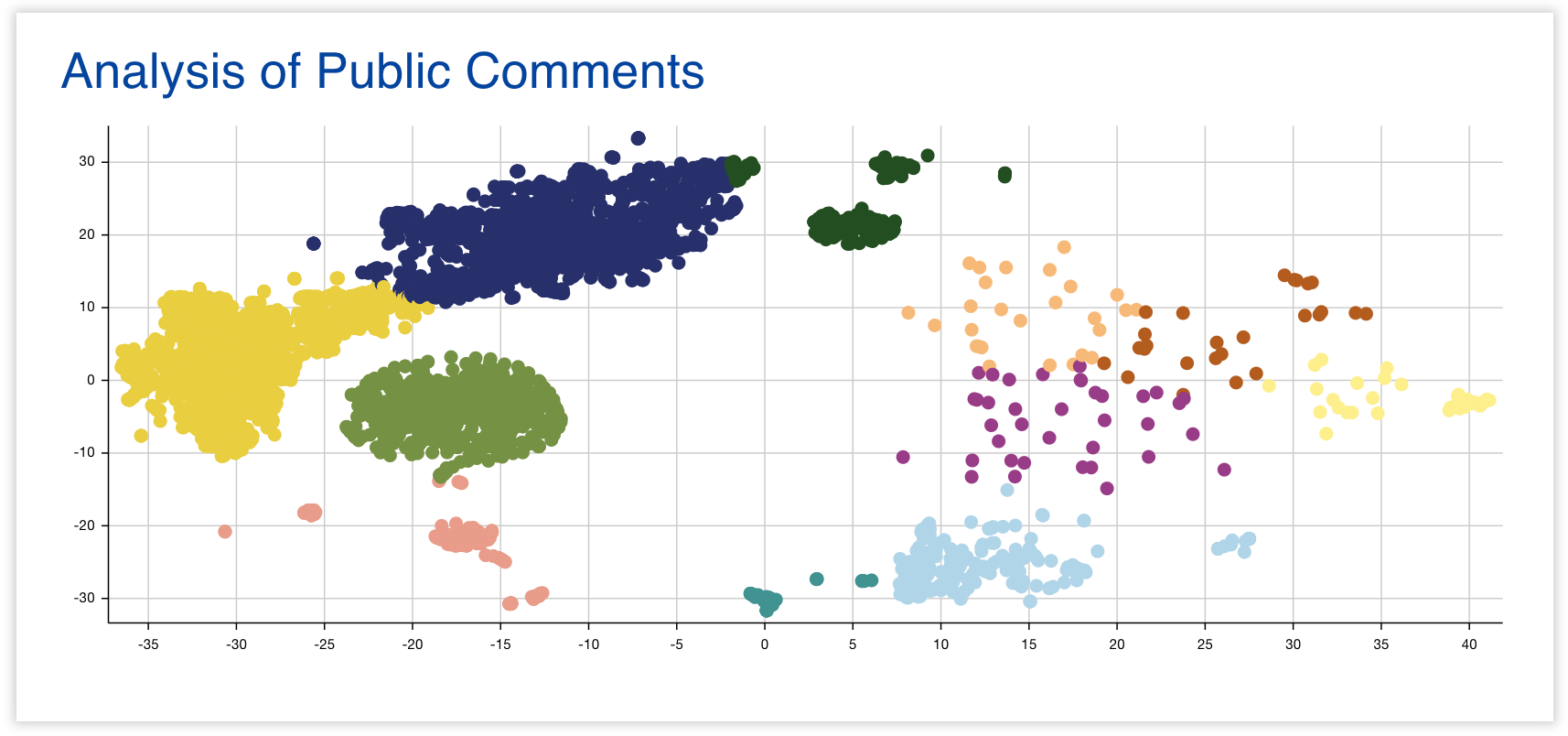
We also make note of "tagged words", words that represent the main topic or feeling of a given document. They help people who are interested in a particular topic find all documents and comments relating to that topic.
We thank our interns for their work this past summer and we look forward to seeing what they will build next. To see our continued work on this project, check out our prototype site at dev.govpinions.io. To see the interns' presentation from the end of the summer, check out their demo video here.
Special thanks to Hayato Gibbons for assisting with the implementation of machine learning algorithms and example data pipelines.
Join our next internship class
The summer of 2022 is rapidly approaching which means it is time for our next batch of interns. Interested? Apply here.