Simple Reinforcement Learning Applications in FedTech


Introduction
Reinforcement learning (RL) offers a powerful framework for optimizing complex operational workflows in federal technology environments—particularly where agencies must balance competing priorities, adapt to changing conditions, and operate under strict resource and policy constraints. Unlike traditional rule-based systems, RL enables an agent to learn effective decision strategies through interaction with a simulated environment, receiving feedback in the form of rewards tied to mission objectives.
Federal grant processing is a strong candidate for this approach. Agencies must continuously trade off application quality, processing timeliness, reviewer capacity, and programmatic balance across categories. These challenges naturally lend themselves to a multi-objective optimization problem, where static heuristics often fall short.
In this post, we walk through a simplified example of how reinforcement learning can be used as a decision-support and simulation tool for grant review workflows. We build a custom RL environment that models application arrivals, reviewer allocation decisions, and capacity constraints, and then demonstrate how an RL agent can learn to improve throughput, manage backlogs, and prioritize higher-quality applications—all within a controlled, low-risk simulation setting.
Code shared here: https://github.com/tgagne-capitaltg/RL-in-govTech-Tutorial.
Problem Overview: Federal Grant Review Workflow
To ground this discussion, we model a simplified federal grant review process as a reinforcement learning environment. The objective is not to automate funding decisions, but to explore how intelligent allocation strategies can improve operational efficiency while respecting policy constraints.
Operational Goals
- Maximize the quality of reviewed and funded applications
- Minimize processing delays and backlog growth
- Balance workload across program categories to support fairness objectives
- Operate within fixed reviewer capacity constraints
Simulation Scope and Assumptions
This example intentionally abstracts real-world complexity in order to focus on core decision dynamics:
- Applications arrive in periodic batches across multiple program categories
- Each batch includes a volume of applications and an average quality score
- Reviewer productivity is assumed to be uniform
- The agent’s decision is how to allocate limited reviewers across categories at each time step
- Rewards reflect trade-offs between throughput, quality, backlog size, and resource misuse
While simplified, this structure captures many of the key pressures present in real federal grant operations and provides a foundation for experimentation and policy analysis.
Step 1: Defining a Custom Reinforcement Learning Environment
At the core of any RL solution is a well-defined environment that encodes system dynamics, constraints, and objectives. In this example, we define a custom gymnasium environment that represents a grant review workflow. The environment exposes:
- A state describing incoming application volume, average quality, and existing backlog per category
- An action space allowing the agent to allocate reviewers across categories, subject to capacity limits
- A reward function that incentivizes timely processing of high-quality applications while penalizing excessive backlog growth and over-allocation of reviewers
This design allows us to experiment with different reward formulations and constraints, which is critical in federal contexts where policy objectives may vary by program or administration.
import gymnasium as gym
import numpy as np
class GrantProcessingEnv(gym.Env):
def __init__(self):
super(GrantProcessingEnv, self).__init__()
self.num_categories = 3 #e.g. state, NGO, research
self.max_reviewers = 10
self.max_batch_size = 20
self.step_count = 0
self.max_steps = 50
# Action: How many reviewers to allocate to each category?
self.action_space = gym.spaces.MultiDiscrete([self.max_reviewers + 1] * self.num_categories)
# Observation: for each cateogy - number of apps, average score, backlog
low_obs = np.array([0, 0.0, 0] * self.num_categories, dtype=np.float32)
high_obs = np.array([self.max_batch_size, 1.0, 100] * self.num_categories, dtype=np.float32)
self.observation_space = gym.spaces.Box(low=low_obs, high=high_obs)
self.reset()
def reset(self, seed=None, options=None):
super().reset(seed=seed) # Call the parent class reset method
self.step_count = 0
self.backlog = np.zeros(self.num_categories, dtype=int)
self.state = self._generate_batch()
return self.state, {}
def _generate_batch(self):
# simulate new applications per category
self.batch_apps = np.random.randint(1, self.max_batch_size, size=self.num_categories)
self.avg_scores = np.random.rand(self.num_categories)
state = []
for i in range(self.num_categories):
state += [self.batch_apps[i], self.avg_scores[i], self.backlog[i]]
return np.array(state, dtype=np.float32)
def step(self, action):
self.step_count += 1
reward = 0.0
# Convert action in to review allocations
reviewers_allocated = np.clip(action, 0, self.max_reviewers)
total_allocated = np.sum(reviewers_allocated)
if total_allocated > self.max_reviewers:
# penalty fo exceeding available reviewers
reward -= 5.0
for i in range(self.num_categories):
processed = min(reviewers_allocated[i] * 2, self.batch_apps[i] + self.backlog[i])
self.backlog[i] = max(0, self.batch_apps[i] + self.backlog[i] - processed)
# reward based on processing high-score applications
quality_factor = self.avg_scores[i]
reward += processed * quality_factor
terminated = self.step_count >= self.max_steps
self.state = self._generate_batch()
truncated = False # Assuming no truncation for now
info = {}
return self.state, reward, terminated, truncated, info
def render(self):
print(f"Step {self.step_count}, Backlog: {self.backlog}")
Before training an RL agent, we establish a baseline by running the environment using random reviewer allocation decisions. This provides a point of comparison for evaluating whether learned policies meaningfully improve outcomes beyond naïve or ad hoc strategies. In practice, agencies often rely on static rules or manual heuristics; a random policy serves as a conservative lower bound for performance.
env = GrantProcessingEnv()
obs, info = env.reset()
print("--- Simulation Started ---")
print(f"Initial Observation: {obs}")
print(f"Number of Categories: {env.num_categories}")
print(f"Maximum Reviewers available: {env.max_reviewers}")
print(f"Maximum Batch Size: {env.max_batch_size}")
# Initialize variables to track performance
total_reward = 0
steps_taken = 0
for _ in range(env.max_steps): # Loop up to max_steps
steps_taken += 1
action = env.action_space.sample() # Take a random action (allocate reviewers)
# Print details before taking the step
print(f"\n--- Step {steps_taken} ---")
print(f"Allocating Reviewers (Action): {action}")
# Print details about the current state (observation)
current_state_details = {}
for i in range(env.num_categories):
start_idx = i * 3
current_state_details[f'Category {i+1}'] = {
'Batch Apps': obs[start_idx],
'Avg Score': obs[start_idx + 1],
'Backlog': obs[start_idx + 2]
}
print("Current State Details:")
for category, details in current_state_details.items():
print(f" {category}: {details}")
obs, reward, terminated, truncated, info = env.step(action) # Take a step in the environment
total_reward += reward # Accumulate the reward
# Print details after taking the step
print(f"Reward received: {reward:.2f}")
print(f"New Observation: {obs}")
env.render() # Render custom information about the environment state (e.g., backlog)
if terminated:
print("\nEpisode terminated.")
break
env.close() # Close the environment resources
print("\n--- Simulation Finished ---")
print(f"Total Steps Taken: {steps_taken}")
print(f"Total Accumulated Reward: {total_reward:.2f}")
# Provide a simple analysis of the simulation run
print("\n--- Final Analysis ---")
if terminated:
print(f"The simulation ran for the maximum allowed steps ({env.max_steps}).")
else:
print(f"The simulation ended early after {steps_taken} steps (reason: {info.get('termination_reason', 'unknown')}).")
print(f"The final backlog for each category is: {env.backlog}")
# Based on the total reward, give a qualitative assessment
if total_reward > 0:
print("The agent achieved a positive total reward, suggesting it processed some high-scoring applications efficiently.")
elif total_reward < 0:
print("The agent received a negative total reward, possibly due to penalties (e.g., over-allocating reviewers) or not processing applications effectively.")
else:
print("The agent achieved a total reward of zero, indicating minimal processing or balanced rewards and penalties.")
print("Note: This simulation uses random actions. Training an RL agent would involve learning optimal allocation strategies.")
Training an RL Agent for Reviewer Allocation
With the simulation environment in place, we can now train a reinforcement learning agent to learn improved allocation strategies over time. In this example, we use the Proximal Policy Optimization (PPO) algorithm from Stable-Baselines3, a widely used and well-tested RL method for continuous decision-making problems.
The agent is trained over multiple simulated episodes, each representing a complete grant review cycle. During training, the agent learns to balance competing objectives—processing speed, application quality, backlog management, and capacity limits—based solely on feedback from the reward function.
After training, we evaluate the learned policy and benchmark its performance against the random baseline to assess whether the agent has discovered more effective allocation strategies.
import numpy as np
import gymnasium as gym
from gymnasium import spaces
from stable_baselines3 import PPO
from stable_baselines3.common.vec_env import DummyVecEnv
import matplotlib.pyplot as plt
# --- Environment Definition ---
class GrantProcessingEnv(gym.Env):
def __init__(self):
super().__init__()
self.num_categories = 3
self.max_reviewers = 10
self.max_batch_size = 20
self.step_count = 0
self.max_steps = 50
self.action_space = spaces.MultiDiscrete([self.max_reviewers + 1] * self.num_categories)
low_obs = np.array([0, 0.0, 0] * self.num_categories, dtype=np.float32)
high_obs = np.array([self.max_batch_size, 1.0, 100] * self.num_categories, dtype=np.float32)
self.observation_space = spaces.Box(low=low_obs, high=high_obs)
def reset(self, seed=None, options=None):
super().reset(seed=seed)
self.step_count = 0
self.backlog = np.zeros(self.num_categories, dtype=int)
self.state = self._generate_batch()
return self.state, {}
def _generate_batch(self):
self.batch_apps = np.random.randint(1, self.max_batch_size, size=self.num_categories)
self.avg_scores = np.random.rand(self.num_categories)
return np.array([
[self.batch_apps[i], self.avg_scores[i], self.backlog[i]]
for i in range(self.num_categories)
], dtype=np.float32).flatten() # Flatten the array to match the observation space shape
def step(self, action):
self.step_count += 1
reward = 0.0
reviewers_allocated = np.clip(action, 0, self.max_reviewers)
total_allocated = np.sum(reviewers_allocated)
if total_allocated > self.max_reviewers:
reward -= 5.0 # Penalty for over-allocation
for i in range(self.num_categories):
processed = min(reviewers_allocated[i] * 2, self.batch_apps[i] + self.backlog[i])
self.backlog[i] = max(0, self.batch_apps[i] + self.backlog[i] - processed)
reward += processed * self.avg_scores[i] # Reward: quantity × quality
# Add a penalty for the total backlog size
backlog_penalty_factor = 0.1 # You can adjust this factor
reward -= np.sum(self.backlog) * backlog_penalty_factor
# Consider adding a term for fairness (e.g., penalty for high variance in backlog)
# if self.step_count > 0: # Avoid calculating variance on the first step
# backlog_variance = np.var(self.backlog)
# fairness_penalty_factor = 0.05 # You can adjust this factor
# reward -= backlog_variance * fairness_penalty_factor
terminated = self.step_count >= self.max_steps
self.state = self._generate_batch()
return self.state, reward, terminated, False, {}
# --- Train with Stable-Baselines3 ---
env = DummyVecEnv([lambda: GrantProcessingEnv()])
model = PPO("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=10000)
# --- Evaluate Agent ---
episode_rewards = []
for _ in range(20):
obs = env.reset()
done = False
total_reward = 0
# The DummyVecEnv returns 4 values: obs, reward, done, info
while not done:
action, _ = model.predict(obs)
obs, reward, done, info = env.step(action) # Corrected unpacking
total_reward += reward[0]
episode_rewards.append(total_reward)
# Generate random agent rewards for comparison
random_episode_rewards = []
env_random = GrantProcessingEnv() # Create a new instance for random agent simulation
for _ in range(20): # Run for the same number of episodes as PPO evaluation
obs, info = env_random.reset()
done = False
total_reward_random = 0
while not done:
action = env_random.action_space.sample() # Random action
obs, reward, terminated, truncated, info = env_random.step(action)
total_reward_random += reward
done = terminated or truncated
random_episode_rewards.append(total_reward_random)
env_random.close()
# Plotting both
plt.figure(figsize=(12, 6))
plt.plot(episode_rewards, marker='o', label="PPO Agent")
plt.plot(random_episode_rewards, marker='x', linestyle='--', label="Random Agent")
plt.title("Total Reward per Episode: PPO vs Random Agent")
plt.xlabel("Episode")
plt.ylabel("Total Reward")
plt.grid(True)
plt.legend()
plt.tight_layout()
plt.show()
Interpreting the Results
Total reward accumulated over an episode reflects how effectively the agent balances review throughput, application quality, and operational constraints. Compared to the random baseline, the trained PPO agent consistently achieves higher rewards, indicating improved decision-making.
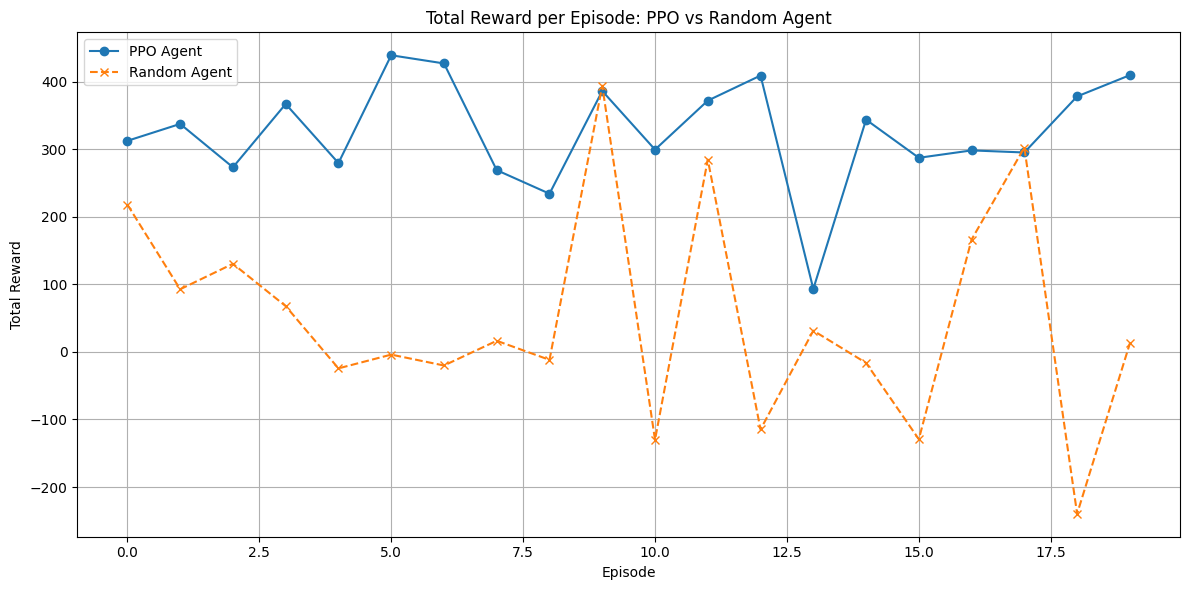
Specifically, the learned policy:
- Avoids systematic over-allocation of reviewers, reducing penalty costs
- Prioritizes categories with higher-quality or growing backlogs
- Maintains backlog levels within manageable bounds rather than aggressively over-processing low-value applications
These behaviors emerge without explicit rules, highlighting how RL can adaptively discover strategies aligned with mission objectives.
Understanding an Episode
Each episode represents a full grant review cycle consisting of multiple decision periods. At the start of an episode, the environment resets with no initial backlog. At each step:
- A new batch of applications arrives across categories
- The agent allocates reviewers based on the current state
- Applications are processed, backlogs update, and a reward is issued
This loop continues for a fixed number of steps, after which the episode terminates and the total reward is recorded. Across many episodes, the agent learns allocation strategies that maximize long-term performance rather than short-term gains.
Key Takeaways for Federal Agencies
- Improve Workflow Efficiency: Reinforcement learning can help agencies explore strategies to reduce processing delays and increase throughput under fixed capacity constraints.
- Support Better Resource Allocation Decisions: By simulating agency-specific workflows, RL agents can learn policies that prioritize higher-impact work while avoiding wasted effort.
- Manage Backlogs Proactively: Reward structures can be tailored to reflect service-level objectives, helping agencies keep backlogs under control.
- Align Automation with Policy Goals: Fairness, program balance, and mission priorities can be encoded directly into the reward function, ensuring that optimization aligns with policy intent.
- Prototype Safely in Simulation: RL enables agencies to test and evaluate advanced optimization strategies in a low-risk environment before considering operational deployment.
Applying this RL Approach to Other Use Cases
While this example focuses on grant review workflows, the same reinforcement learning framework can be applied to a wide range of federal operational challenges involving dynamic resource allocation and competing objectives. By clearly defining state, action, and reward structures, agencies can use RL as a powerful analytical and decision-support tool—augmenting human expertise rather than replacing it.